LAThomson
my personal website!
My work
… in order of recency…
Prism: Automating Science-of-Evals Research for AI Safety
An agent scaffold designed to automate science-of-evals research work.
This scaffold, built on top of [Inspect AI], [Claude Code], and the [Claude Agent SDK], is designed to automate work on understanding eval dynamics and explaining model behaviours with respect to their environment.
A Framework for Eval Awareness
Setting out a conceptual framework for key research directions in evaluation awareness.
This [blog post] was the result of the first three weeks of MATS 9.0, where I developed this framing to help me identify promising and neglected research directions for mitigating eval gaming.
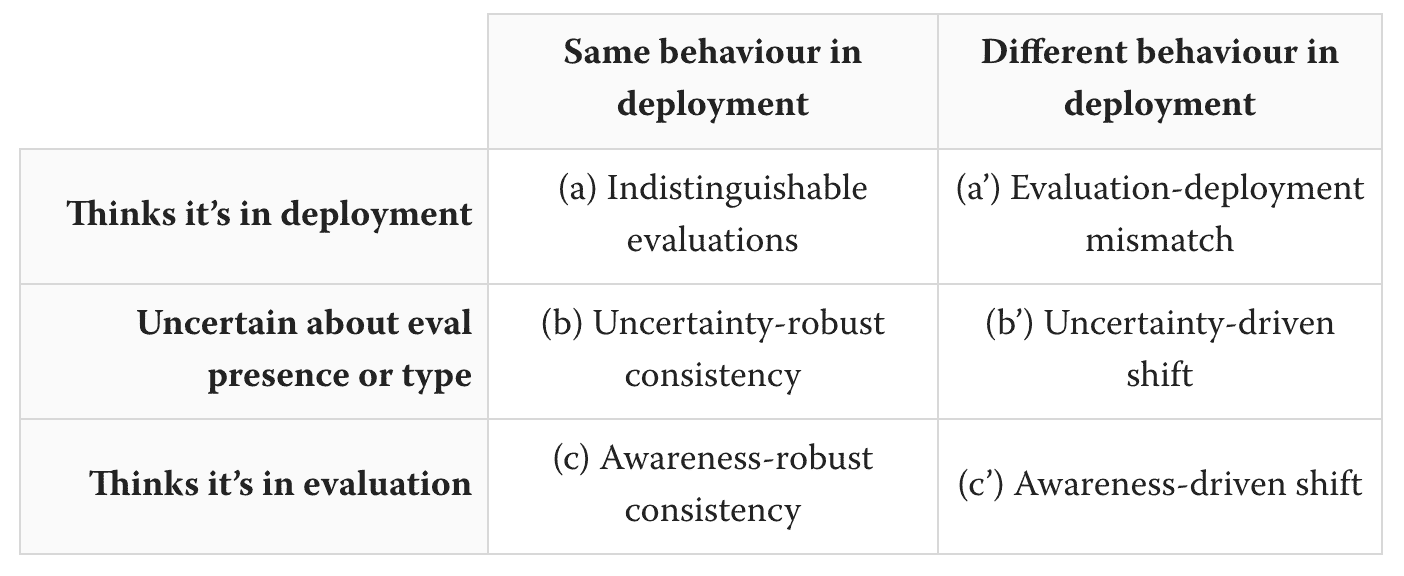
Agentic Monitoring for AI Control
An initial investigation into how we might empower trusted monitors with agency.
See my [blog post] for an introduction to the research direction alongside some initial results and discussion.
Cooperation and Control in Markov Delegation Games
Formalising these two key dimensions along which multi-agent delegation games can produce bad outcomes for humans.
This was carried out as part of my Master’s year at Oxford; see my [report]. [Note: I’d be keen to finish this work some day and turn it into a workshop paper!]
Model Models: Simulating a Trusted Monitor
Can an untrusted model predict how a trusted monitor will score its solutions?
This was part of the Apart Research [AI Control Hackathon] in March 2025; see the [project page] containing a report and the codebase.

Games for AI Control
Introducing a game-theoretic model for AI Control settings.
See the [paper] and [blog post].
Towards shutdownable agents via stochastic choice
Working on a proposal to solve the corrigibility problem by training agents to have incomplete preferences.
I briefly worked on this project through the [Future Impact Group] programme; you can see the resulting [paper] which was accepted to [TAIS 2025].
Tall Tales at Different Scales: Evaluating Scaling Trends For Deception In Language Models
Investigating the extent to which belief consistency and deceptive behaviour scale with model size.
I began working on this project through the AI Safety Hub Labs programme (now [LASR Labs]). See our [blog post] and a [follow-up paper].